
Pelagodes simplvalvae Han & Xue
|
publication ID |
https://doi.org/ 10.5281/zenodo.205134 |
|
DOI |
https://doi.org/10.5281/zenodo.6193389 |
|
persistent identifier |
https://treatment.plazi.org/id/03B687B1-3E2E-6B4B-BCCD-FA8CFE4377DF |
|
treatment provided by |
Plazi |
|
scientific name |
Pelagodes simplvalvae Han & Xue |
| status |
sp. nov. |
Pelagodes simplvalvae Han & Xue , sp. nov.
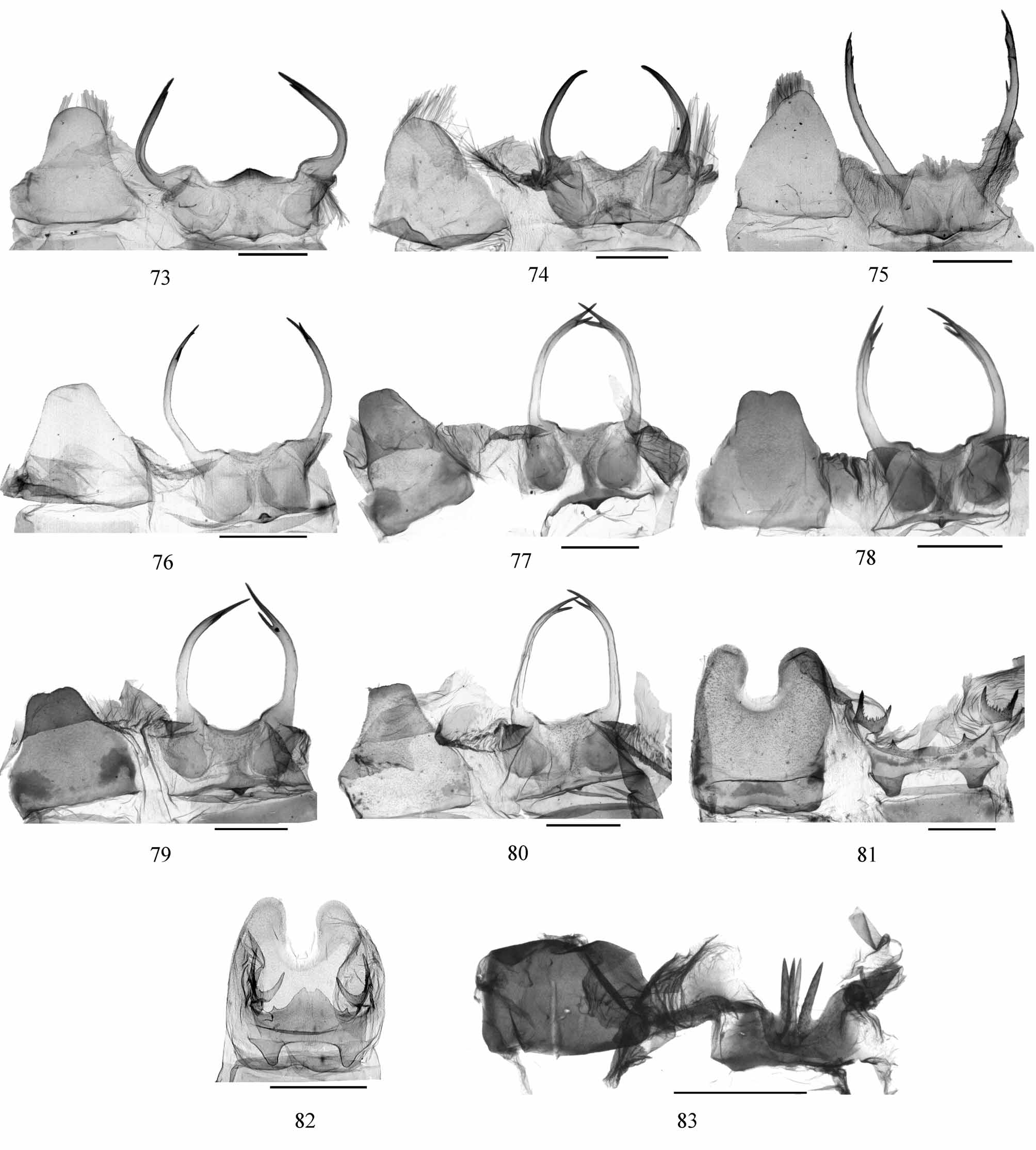
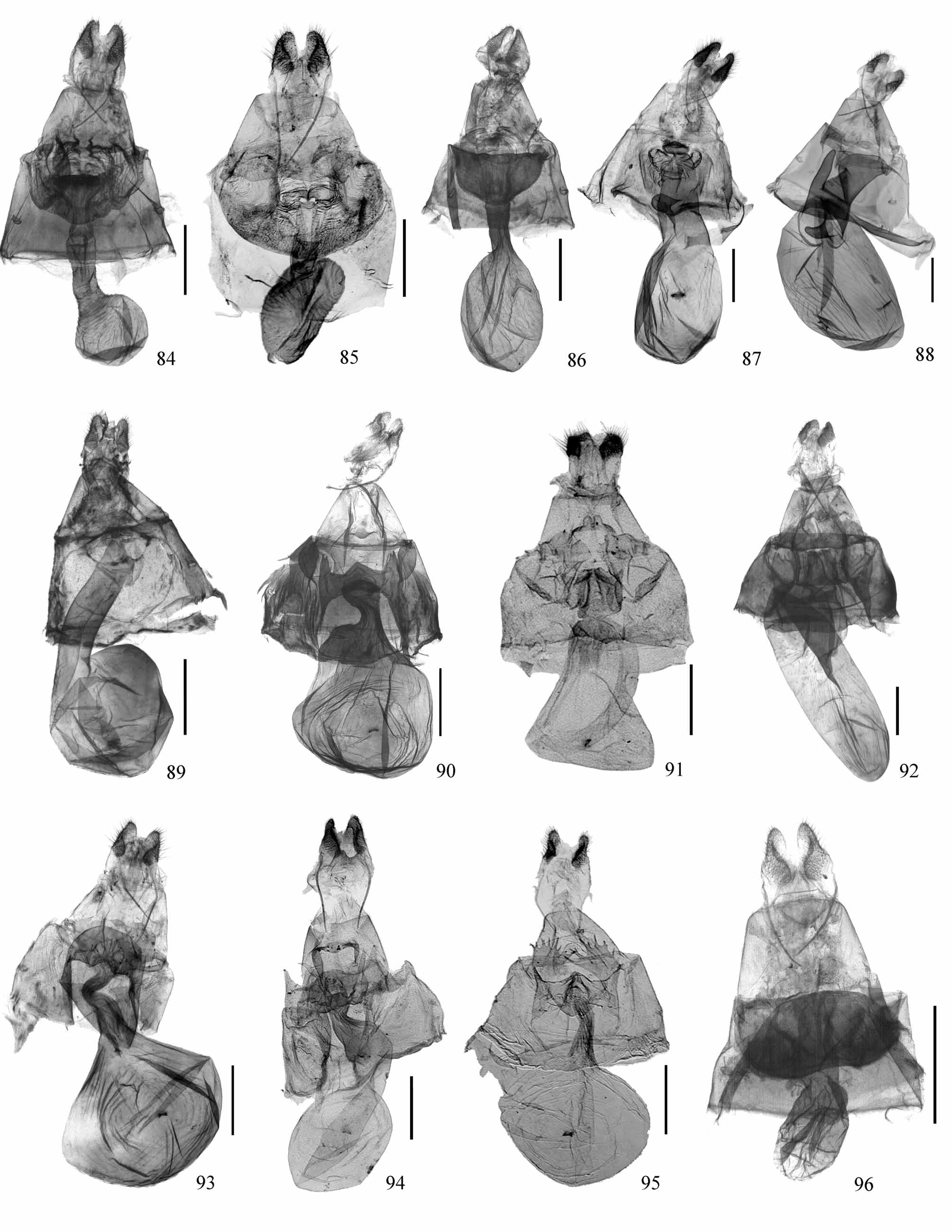
Figs 16 View FIGURES 1 – 20 , 35 View FIGURES 33 – 39 , 53 View FIGURES 40 – 57 , 75 View FIGURES 73 – 83 , 93 View FIGURES 84 – 96
Description. Head: Antenna in male bipectinate for about basal two-thirds, adpressed, filiform terminally, simple filiform in female. Frons dark reddish brown, rough-scaled. Labial palpus tiny, upper surface reddish brown, ventral surface whitish; the third segment in female distinctly elongate. Vertex with anterior half white, posterior half bluish green. Thorax: Dorsal side of thorax bluish green, ventral side white. Hind tibia with two pairs of spurs in both sexes. Forewing length: 313– 14 mm, Ƥ 15 mm. Wings deep bluish green, diffused with white striations. Apex of forewing blunt, that of hind wing protruding; outer margin of forewing slightly curved, that of hind wing slightly angled at middle. Costa a broad yellow band; antemedial line curved from costa to lower margin of cell, then straight and oblique to inner margin; postmedial line straight, almost perpendicular to inner margin. Hind wing with white postmedial line straight from costa to M3, and forming a blunt protrusion below this vein, then slightly sinuous to inner margin. Fringes of both wings yellow, forming a yellow border together with yellow costa of forewing. Venter much paler, streaks on dorsum discernible. Abdomen: Dorsal side of abdomen bluish green, ventral side white. The eighth tergite strongly protruding. The eighth sternite small, but with large, slightly curved lateral processes, bearing three to four small teeth on inner surface and a longer tooth at tip; middle part of posterior margin concave, with another two blunt, triangular protrusions. Male genitalia: Uncus rod-like. Socii very broad. Gnathos lacking basal protrusions, median process small. Valva almost lacking costal extension, only with vestige of small protrusion at middle of costa; ventral margin expanded at base, concave at middle. Juxta with two lateral processes projecting posteriorly. Saccus rounded. Aedeagus short and broad, posterior half sclerotized and scobinate. Female genitalia: Lamella postvaginalis a pair of lateral sclerites, margin serrate with several pointed teeth. Lamella antevaginalis pocket-like. Ductus bursae wrinkled and sinuous. Corpus bursae large, rounded, with a bicornute signum.
Material examined. Holotype, 3, CHINA: Hainan ( IZCAS): Jianfengling, 23.V.1980, coll. Gu Maobin ( Albizzia procera ). Paratypes: Hainan ( IZCAS): Jianfengling, 29.VII.1982, coll. Gu Maobin, 13; Jianfengling, 24.VIII.1982, coll. Liang Chengfeng, 13 (Slide No. 614); Jianfengling, 14.X.1983, coll. Gu Maobin, 1Ƥ (Slide No. 1295).
Diagnosis. The male genitalia of P. simplvalvae are similar to that of P. ogasawarensis ( Inoue, 1994) ( Japan, BMNH Slide No. 17788) on the simple, unadorned valva. But in the latter species, the costa bears a small distinct tooth beyond middle, compared to the indistinct trace of a tiny protrusion more proximally located in P. simplvalvae . In addition, the ventral margin of the valva of P. ogasawarensis is only shallowly concave at middle with the basal half slightly curved, but strongly expanded in the basal half in P. simplvalvae . The male eighth segment is also different as follows: the lateral processes of the eighth sternite are smooth in P. ogasawarensis but bear several small teeth in P. simplvalvae ; the margin between lateral processes bears two triangular protrusions in P. simplvalvae but is only slightly curved in P. ogasawarensis ; the tergite is much narrower in P. simplvalvae than in P. ogasawarensis . The female genitalia are quite different in that the corpus bursae is very large, broad with a signum in P. simplvalvae , but is slender and lacks a signum in P. ogasawarensis .
Biology. From the label data of the holotype, the food plant of this species is recorded as Albizzia procera (Leguminosae) .
Distribution. China (Hainan).
Etymology. The specific name is from the Latin prefix simpl - (=simple) and the Latin word valva, referring to the simple valva of the species.



| IZCAS |
Institute of Zoology, Chinese Academy of Sciences |
No known copyright restrictions apply. See Agosti, D., Egloff, W., 2009. Taxonomic information exchange and copyright: the Plazi approach. BMC Research Notes 2009, 2:53 for further explanation.